
本地AI大模型部署
记录一次本地AI大模型的部署
前言
本人使用的设备的配置是
系统:Windows11
CPU:13th Gen Intel(R) Core(TM) i5-13500HX
内存:16G
显卡:NVIDIA GeForce RTX 4060 Laptop GPU
方法一:GPT4All
优点:全程可视化UI操作,不需要敲命令,只需要安装一个软件即可完成后续的大模型的下载和使用,
缺点:内存占用偏高,在对话的交互上我用的不太舒服,就比如代码的复制粘贴没有像ChatGPT网页版中有个按钮点击就能复制,反而要手动选择后才能复制(后续软件可能会优化)
安装
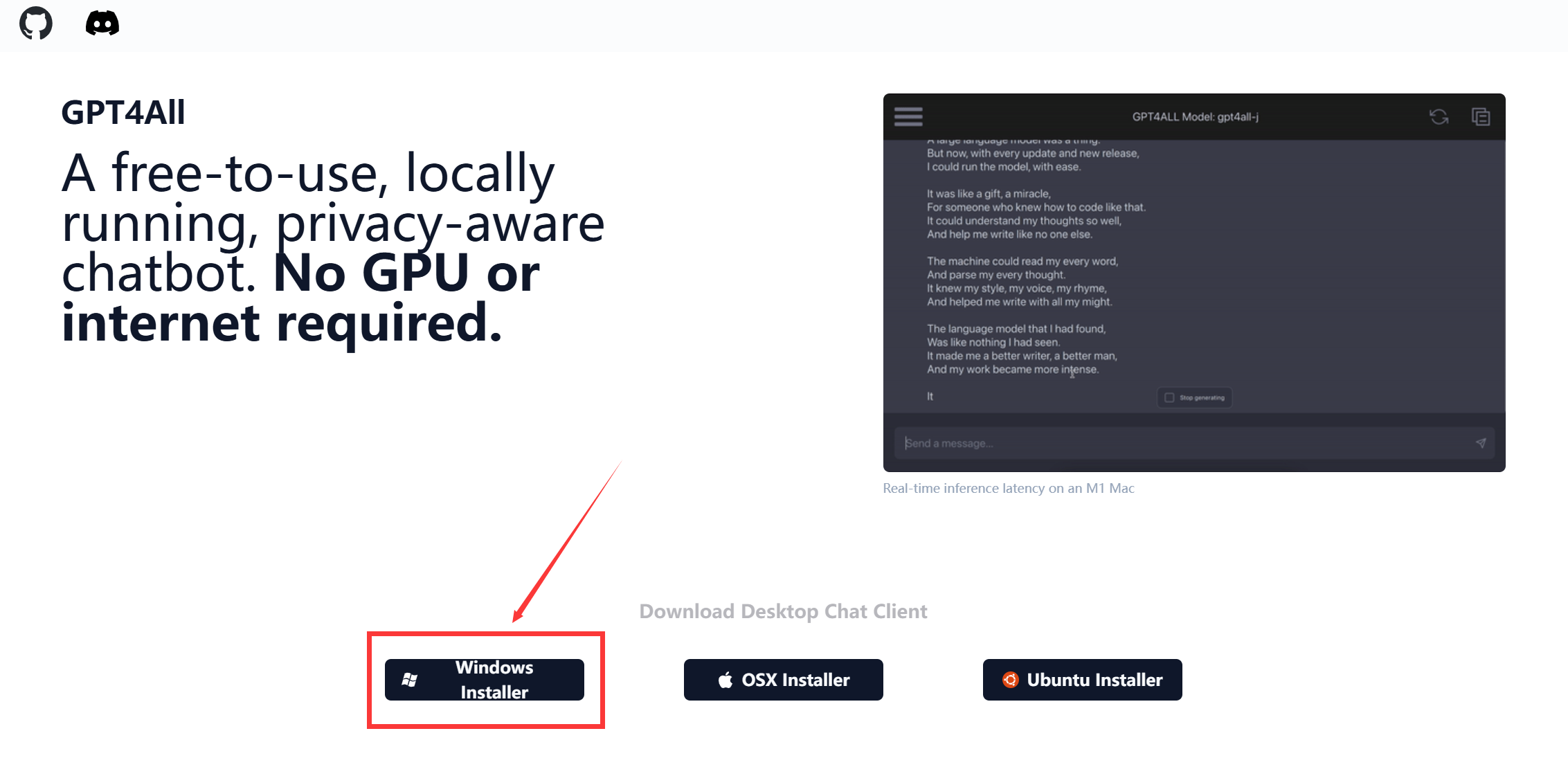
前往官网下载软件
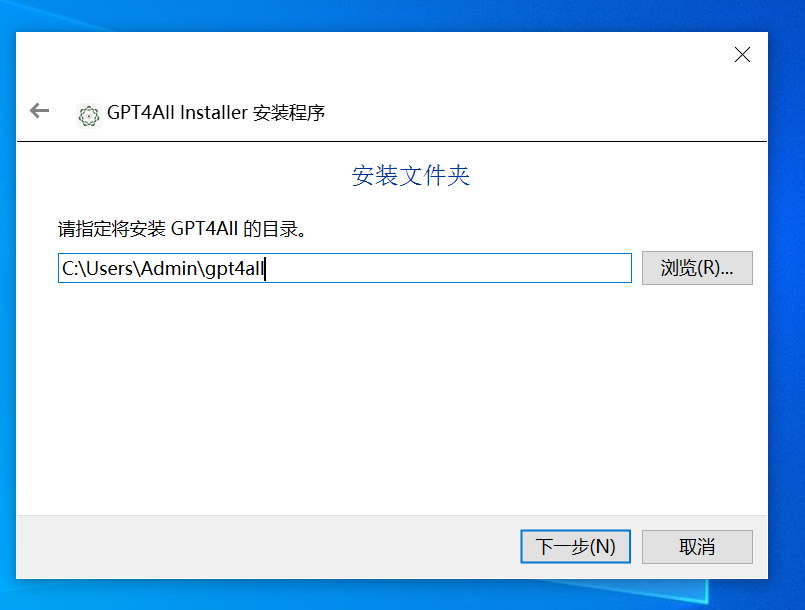
无脑一键安装就可以了,安装路径这里可以改,我这里直接全部默认了
组件默认
等待下载安装完成即可
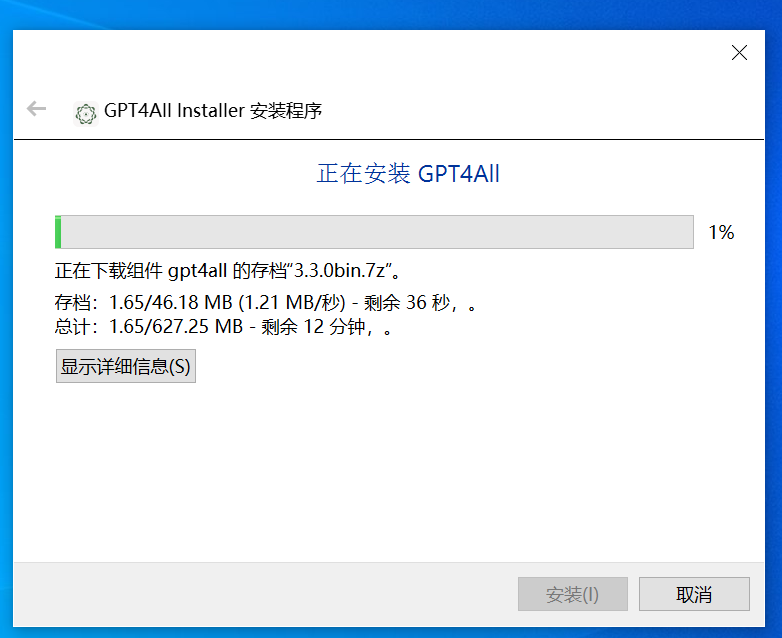
模型下载
可选:可以先去设置里面调整模型的下载目录,否则软件默认把大模型下载到C盘
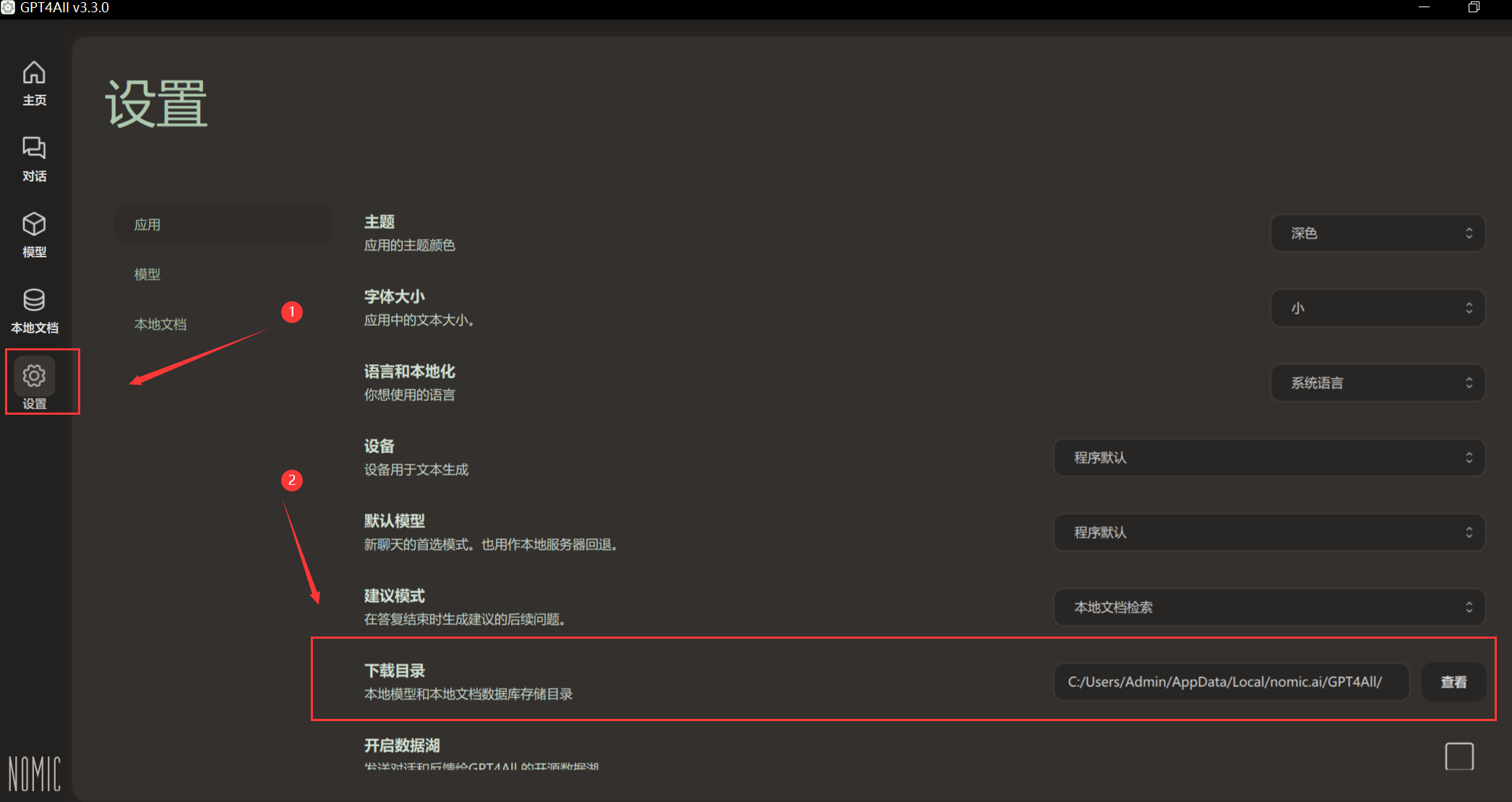
设置完成后点击模型,然后点击添加模型
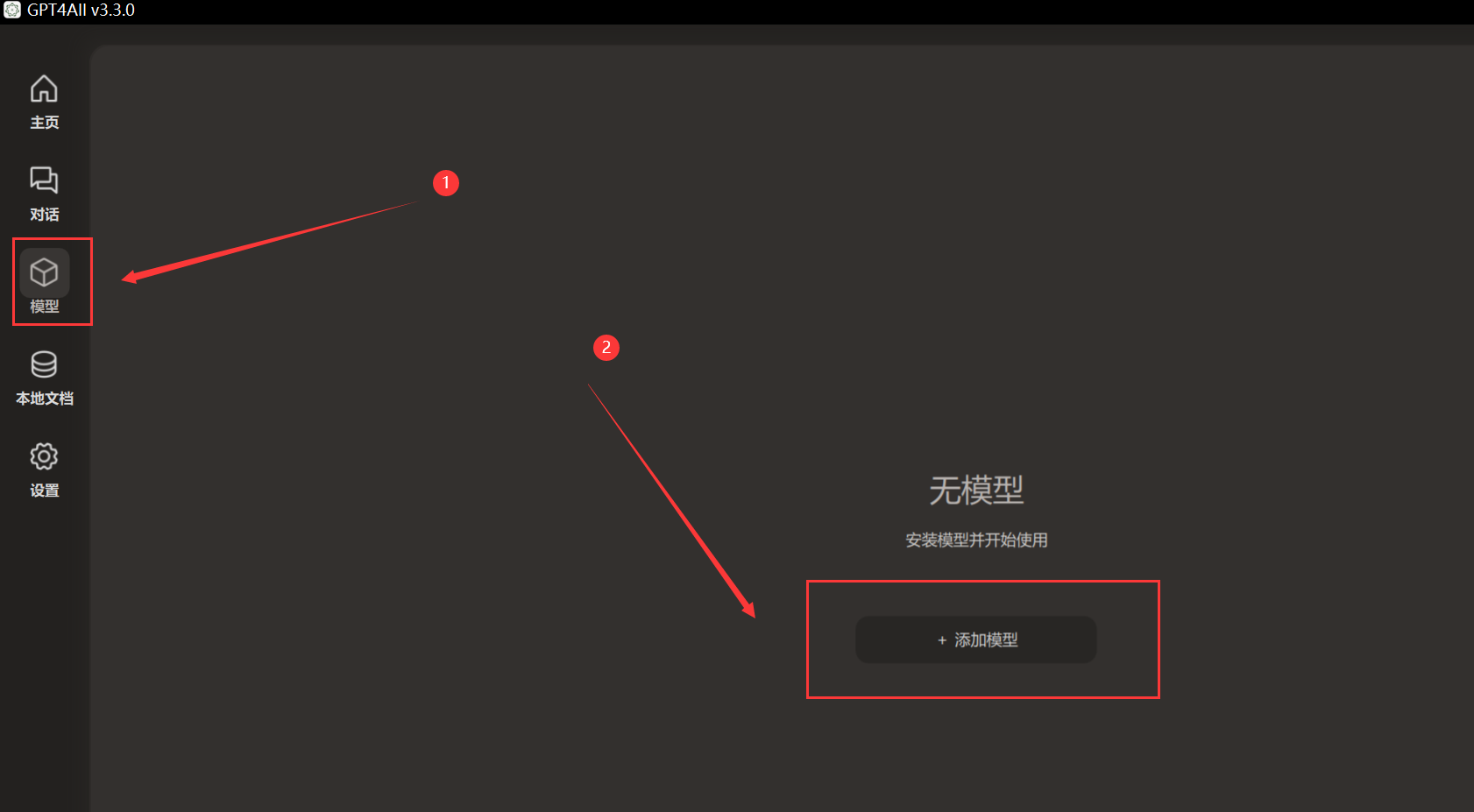
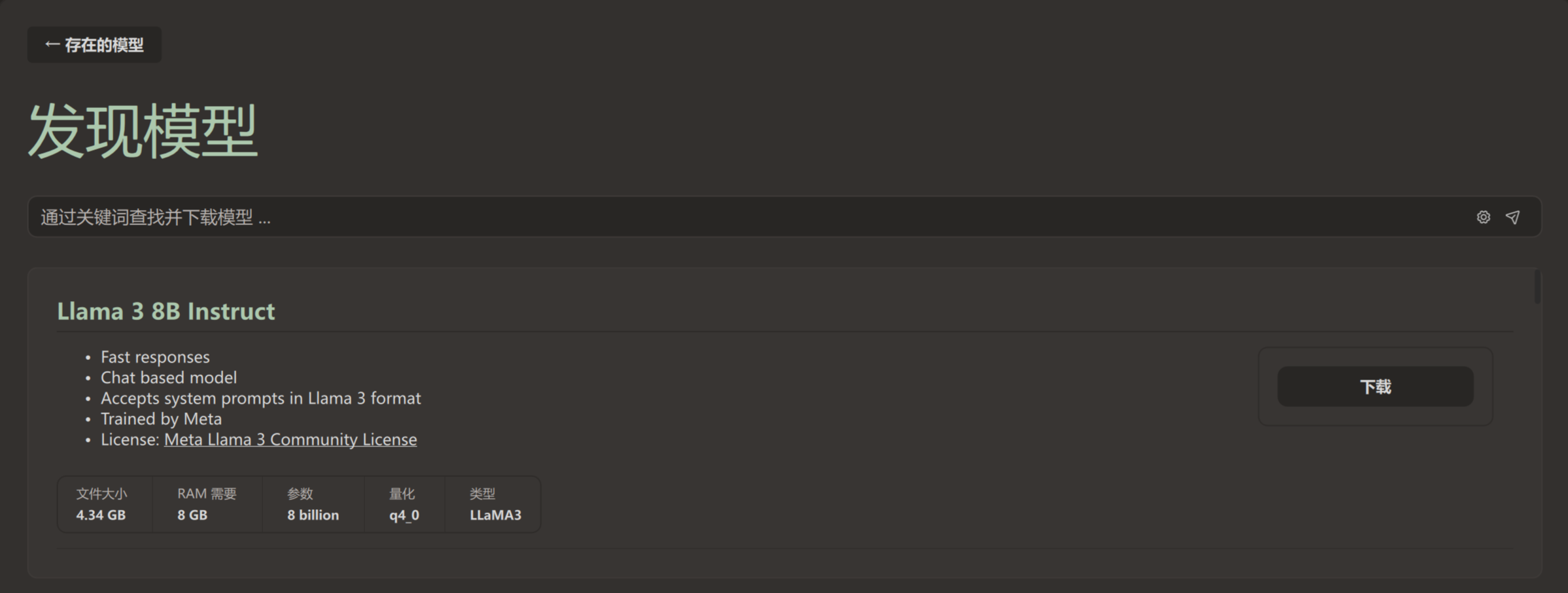
选择一个模型点击下载即可
注:有时可能无法加载模型列表,科学一下再重新打开软件即可,加载出列表就能关了,下载模型时不需要挂着
开始使用
下载完后,点击对话,然后点击载入刚才下载的模型
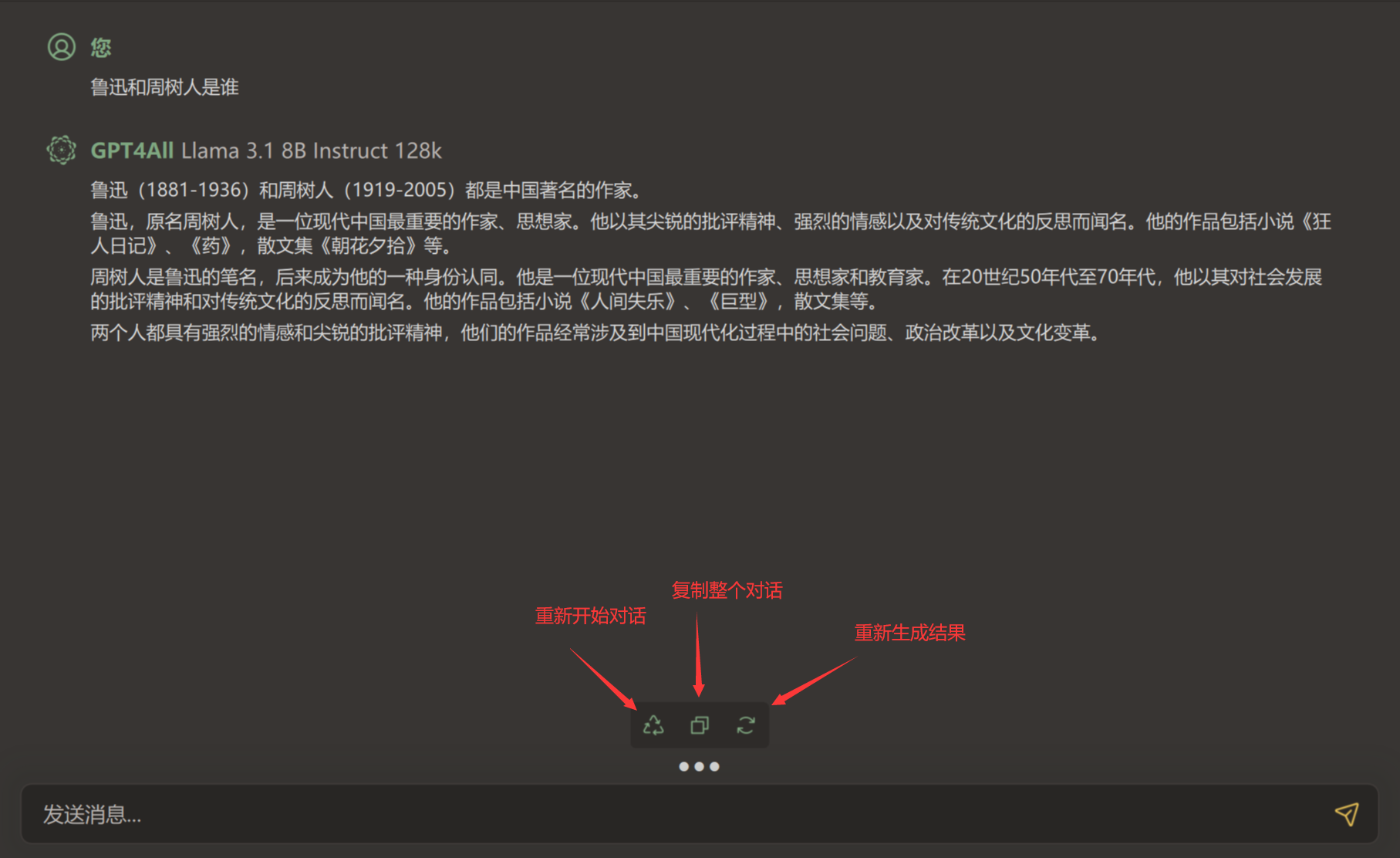
等载入完成后即可开始使用
方法二(推荐):Ollama+Vscode插件Continue
优点:内存占用偏低,可以用CMD窗口直接执行命令启动,在日常交互使用上我觉得比GPT4All要好很多,而且生成的速度略快于GPT4All
缺点:需要使用命令行进行模型下载,软件默认只能装C盘
现在开始教程
安装
前往官网下载Ollama
软件安装非常简单,没有任何配置点击安装即可(强制默认安装C盘)
出现一下弹窗证明安装成功
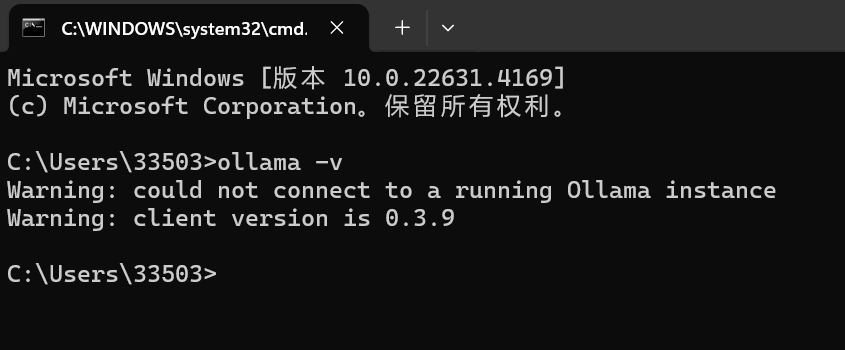
打开命令窗口输入ollama -v出现版本号
模型下载
可选:修改模型下载路径
默认模型下载路径:C:\Users\用户\.ollama\models
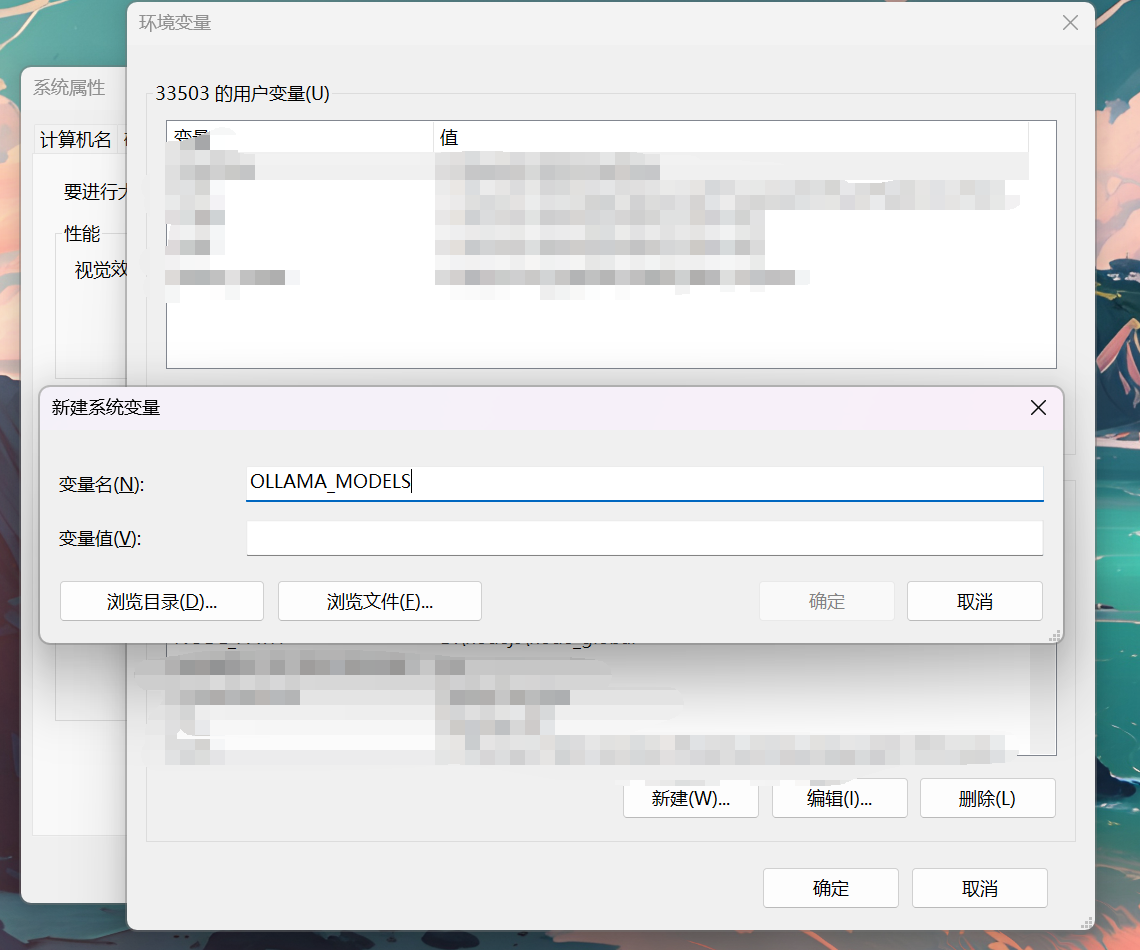
添加系统变量修改模型默认下载路径
变量名:OLLAMA_MODELS
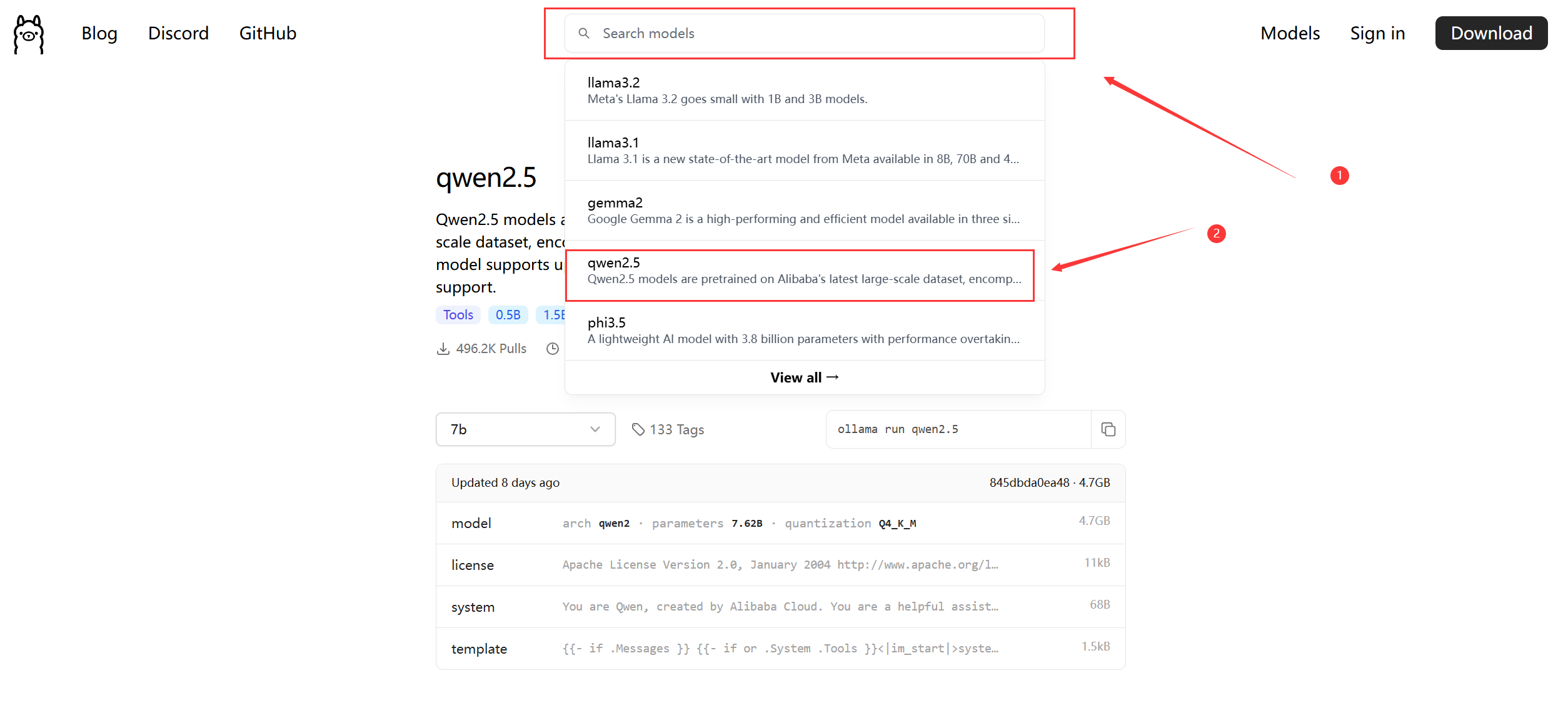
还是前往ollama的官网
在搜索栏搜索想要下载的大模型
这里用qwen2.5为例,假设我想要下载这个模型,复制运行命令
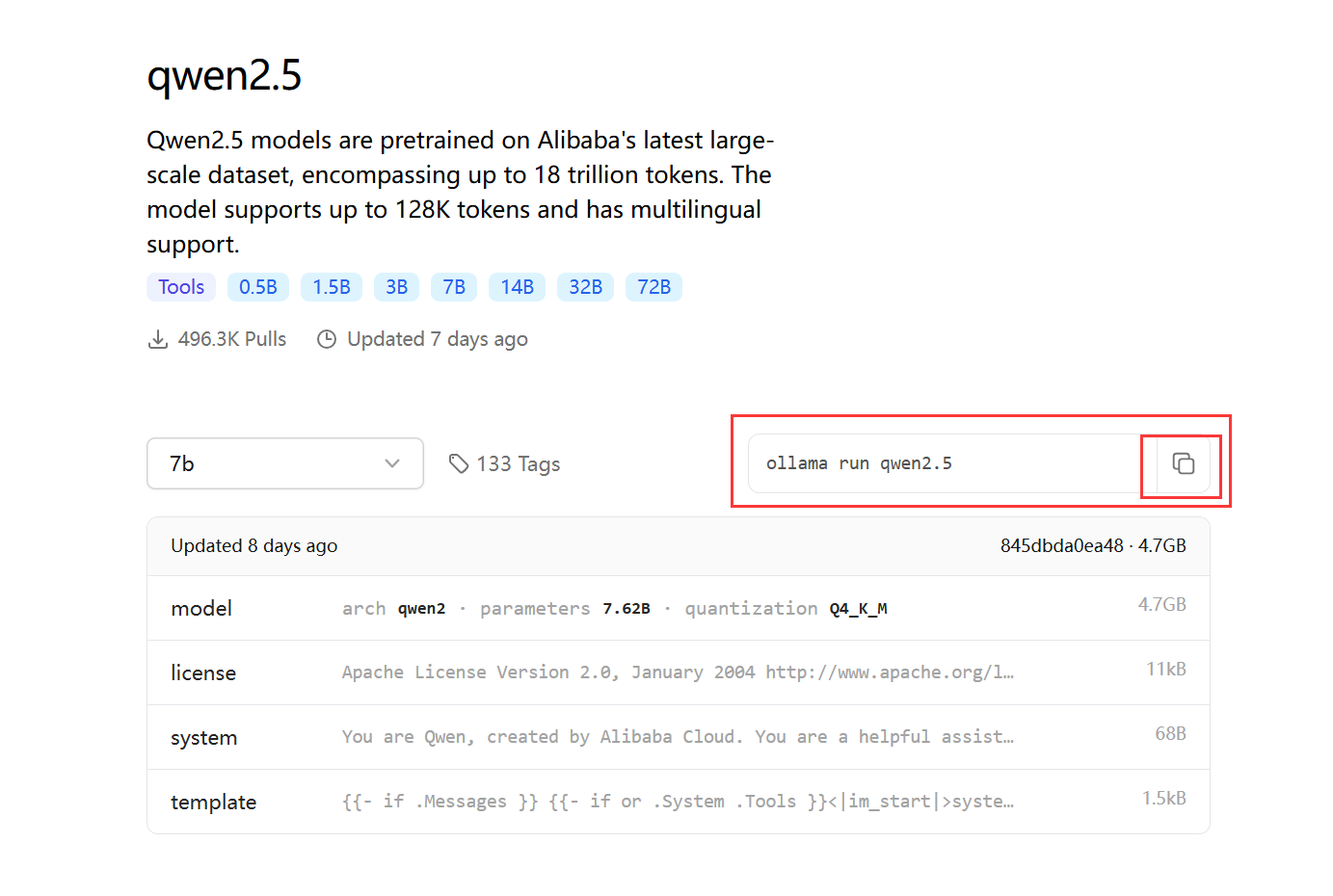
然后在CMD执行,等他下载完成

也可以手动导入本地大模型
参考文章:
Ollama完整教程:本地LLM管理、WebUI对话、Python/Java客户端API应用 - 老牛啊 - 博客园 (cnblogs.com)
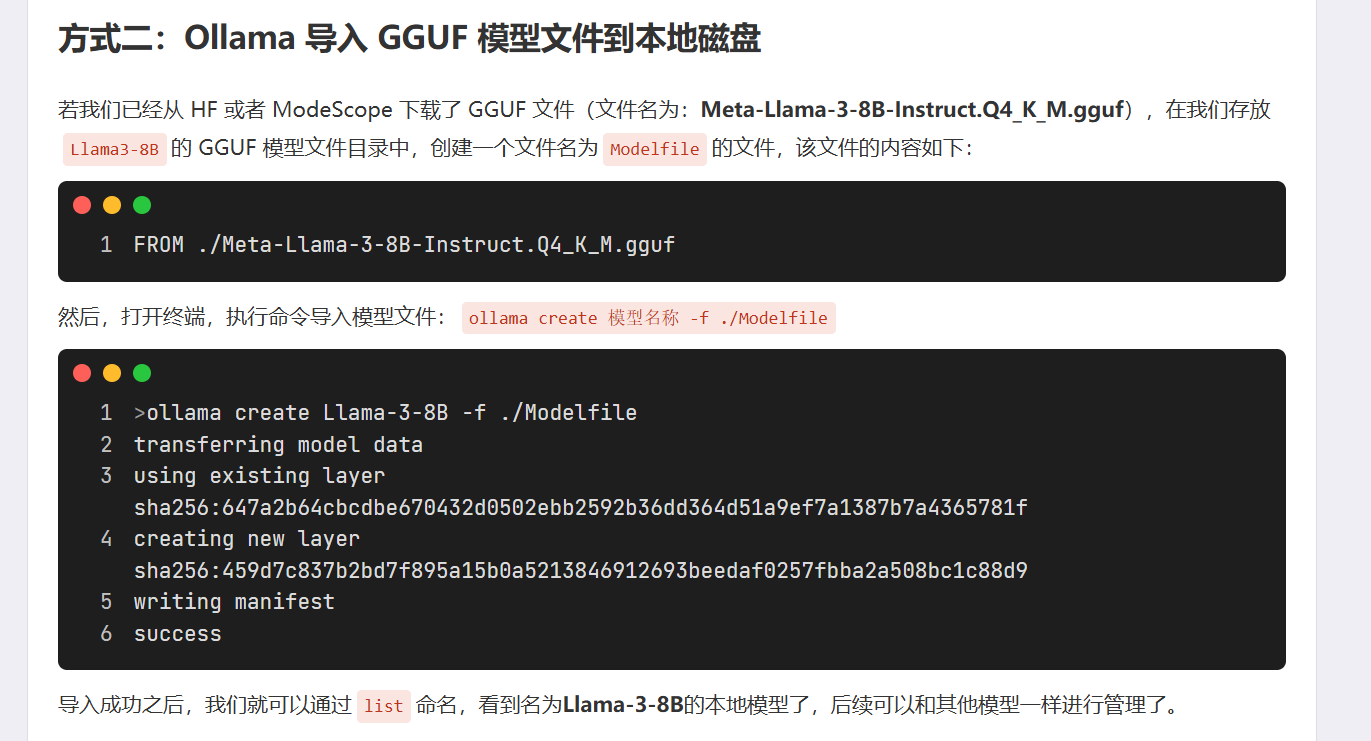
首先新建一个文件,命名为Modelfile,内容为:FROM 模型的路径
1 | // 配置文件 |
然后在CMD命令窗口输入以下命令
1 | // 导入命令 |
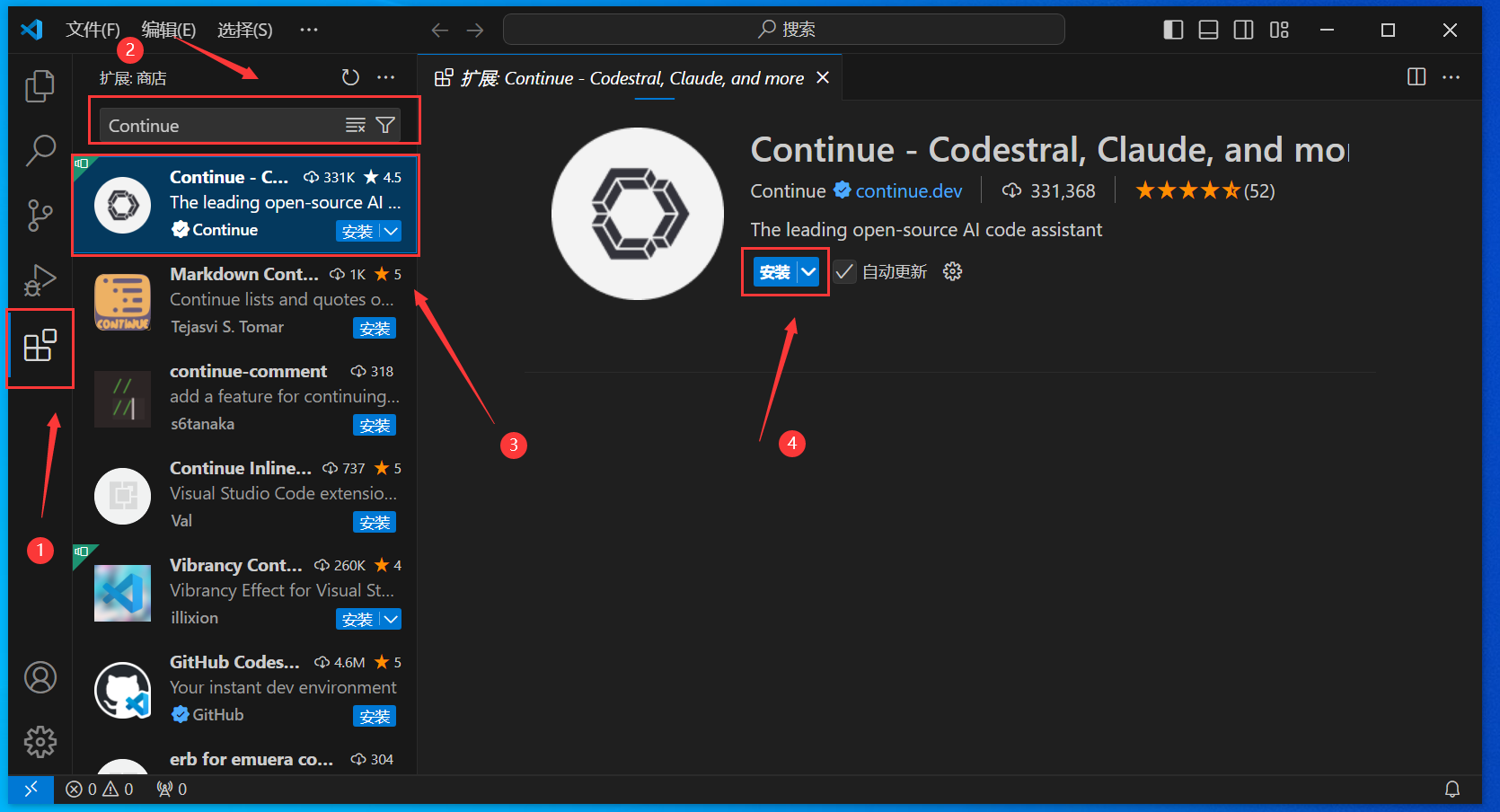
安装Vscode插件Continue
一图流演示安装过程
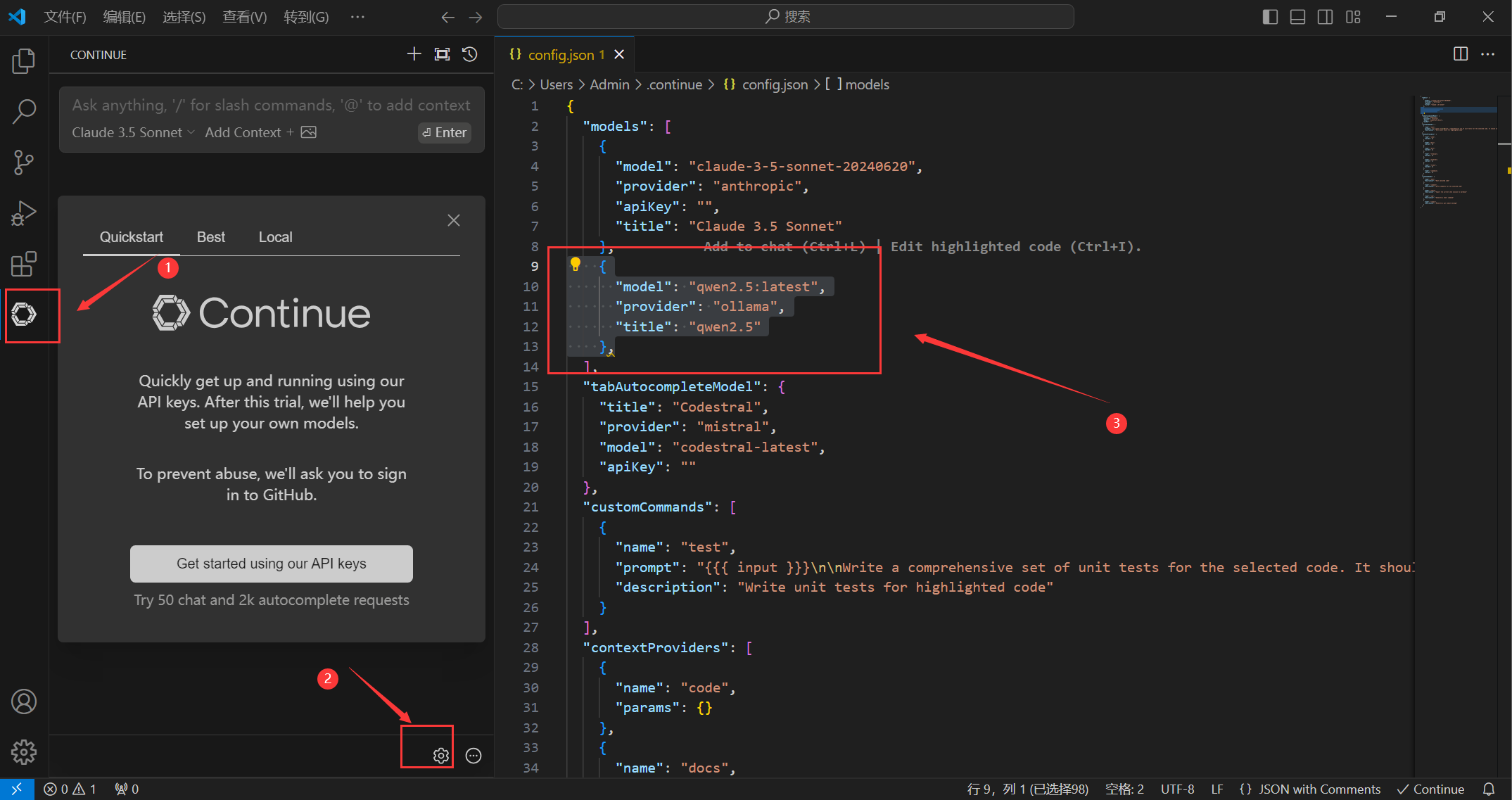
在配置文件中填写以下配置并保存
1 | { |
开始使用
这个方法有两个使用方式
第一种是,下载模型完成后即可直接开始对话
但是cmd命令窗口下对话的内容并不会保存,且无法换行输入(可以复制进去)

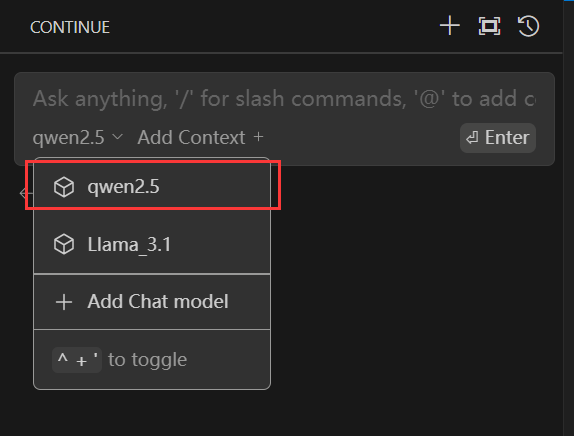
第二种是在VsCode中使用,我也更推荐该方法,使用前先双击打开ollama软件

然后选择模型
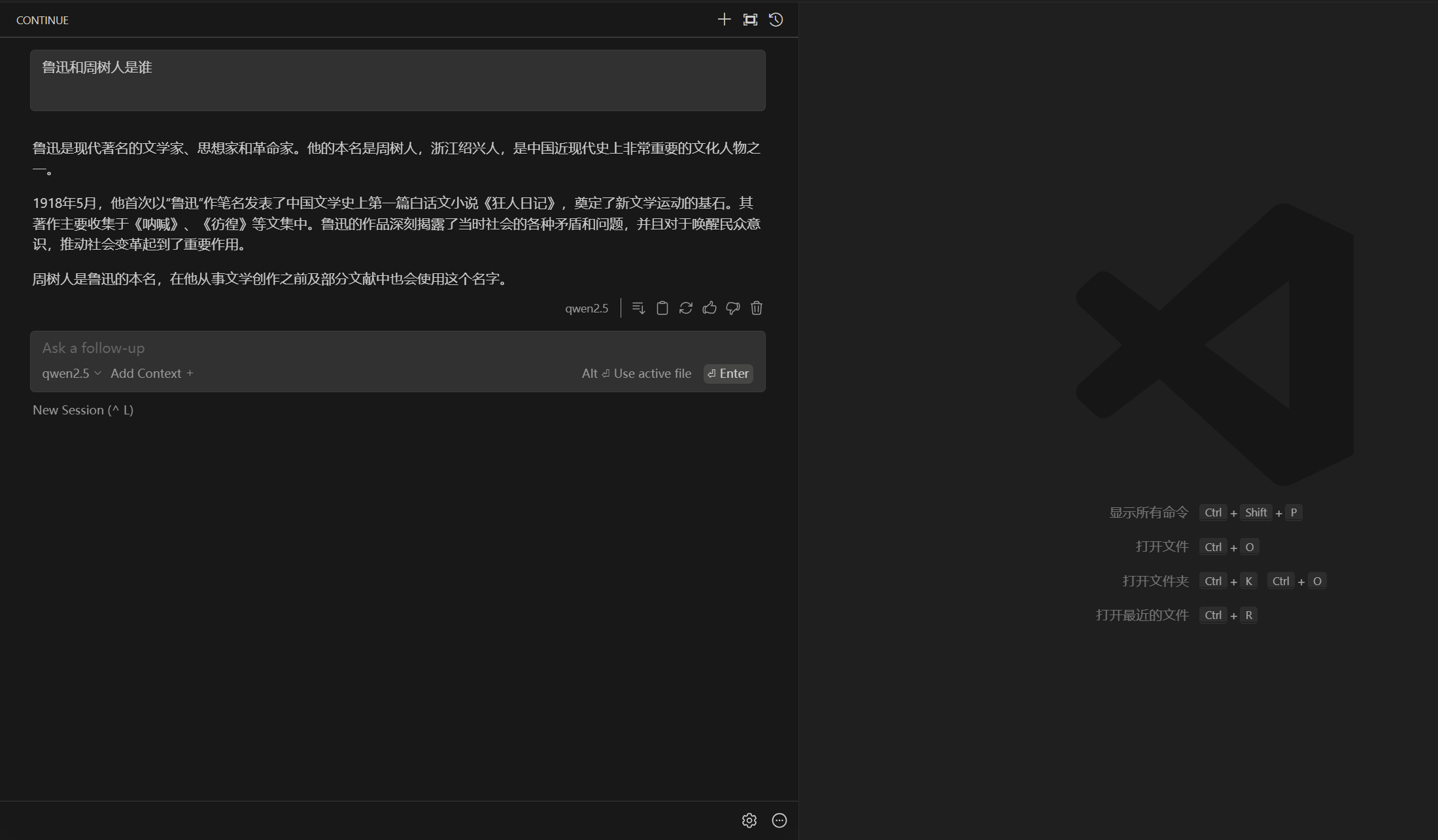
开始对话
本文完~
